Kotlin для анализа данных
Исследовать и анализировать данные приходится не каждый день, но это важный навык для разработчика.
В разработке программного обеспечения анализ данных нужен во многих задачах: например, чтобы разобраться, что на самом деле находится внутри коллекций во время отладки, изучить дампы памяти или базы данных, или обработать JSON-файлы с большим объемом данных при работе с REST API.
Инструменты Kotlin для исследовательского анализа данных (Exploratory Data Analysis, EDA), такие как Kotlin notebooks, Kotlin DataFrame и Kandy, дают богатый набор возможностей, которые помогают развивать аналитические навыки и решать разные задачи:
- Загружать, преобразовывать и визуализировать данные в разных форматах: с инструментами Kotlin EDA можно фильтровать, сортировать и агрегировать данные. Эти инструменты позволяют читать данные прямо в IDE из разных источников, таких как CSV, JSON, SQL-базы данных или файлы Parquet. Все поддерживаемые форматы перечислены в документации DataFrame.
Kandy, инструмент для построения графиков, позволяет создавать широкий набор диаграмм, визуализировать данные и находить закономерности в датасетах.
- Эффективно анализировать данные, хранящиеся в реляционных базах данных: Kotlin DataFrame легко интегрируется с базами данных и предоставляет возможности, похожие на SQL-запросы. Вы можете получать, обрабатывать и визуализировать данные напрямую из разных баз данных.
- Получать и анализировать динамические наборы данных и данные в реальном времени из веб-API: гибкость инструментов EDA позволяет интегрироваться с внешними API через протоколы вроде OpenAPI. Так можно получать данные из веб-API, а затем очищать и преобразовывать их под свои задачи.
Инструменты Kotlin для анализа данных помогают работать с данными на всех этапах. В Kotlin Notebook можно легко загрузить данные простым перетаскиванием. Очистка, преобразование и визуализация выполняются всего несколькими строками кода, а готовые графики можно экспортировать в несколько кликов.
 {width=700}
{width=700}
Ноутбуки
Ноутбук - это интерактивный документ, в котором можно сочетать исполняемый Kotlin-код с текстом, визуализациями и результатами. Его можно представить как Kotlin REPL, дополненный возможностью разбивать код на ячейки, документировать его с помощью Markdown и сразу показывать результаты - от текста до графиков - рядом с кодом, который их создал.
Kotlin предлагает разные решения для ноутбуков: Kotlin Notebook, Datalore и Kotlin-Jupyter Notebook. Они предоставляют удобные возможности для получения, преобразования, исследования и моделирования данных. Эти решения основаны на Kotlin Kernel.
Код можно без проблем переносить между Kotlin Notebook, Datalore и Kotlin-Jupyter Notebook. Создайте проект в одном из Kotlin-ноутбуков и продолжайте работу в другом без проблем совместимости.
 {width=700}
{width=700}
Kotlin Notebook
Kotlin Notebook - это плагин для IntelliJ IDEA, который позволяет создавать ноутбуки на Kotlin. Он переносит привычные возможности IDE в работу с ноутбуками: подсказки и анализ кода в реальном времени, а также интеграцию с проектами.
Kotlin-ноутбуки в Datalore
С Datalore можно использовать Kotlin в браузере сразу, без дополнительной установки. Также можно делиться ноутбуками и запускать их удаленно, совместно работать с другими Kotlin-ноутбуками в реальном времени, получать умные подсказки при написании кода и экспортировать результаты в виде интерактивных или статических отчетов.
Jupyter Notebook с Kotlin Kernel
Jupyter Notebook - это веб-приложение с открытым исходным кодом, которое позволяет создавать документы с кодом, визуализациями и Markdown-текстом, а также делиться ими. Kotlin-Jupyter - это проект с открытым исходным кодом, который добавляет поддержку Kotlin в Jupyter Notebook и позволяет использовать возможности Kotlin в среде Jupyter.
Kotlin DataFrame
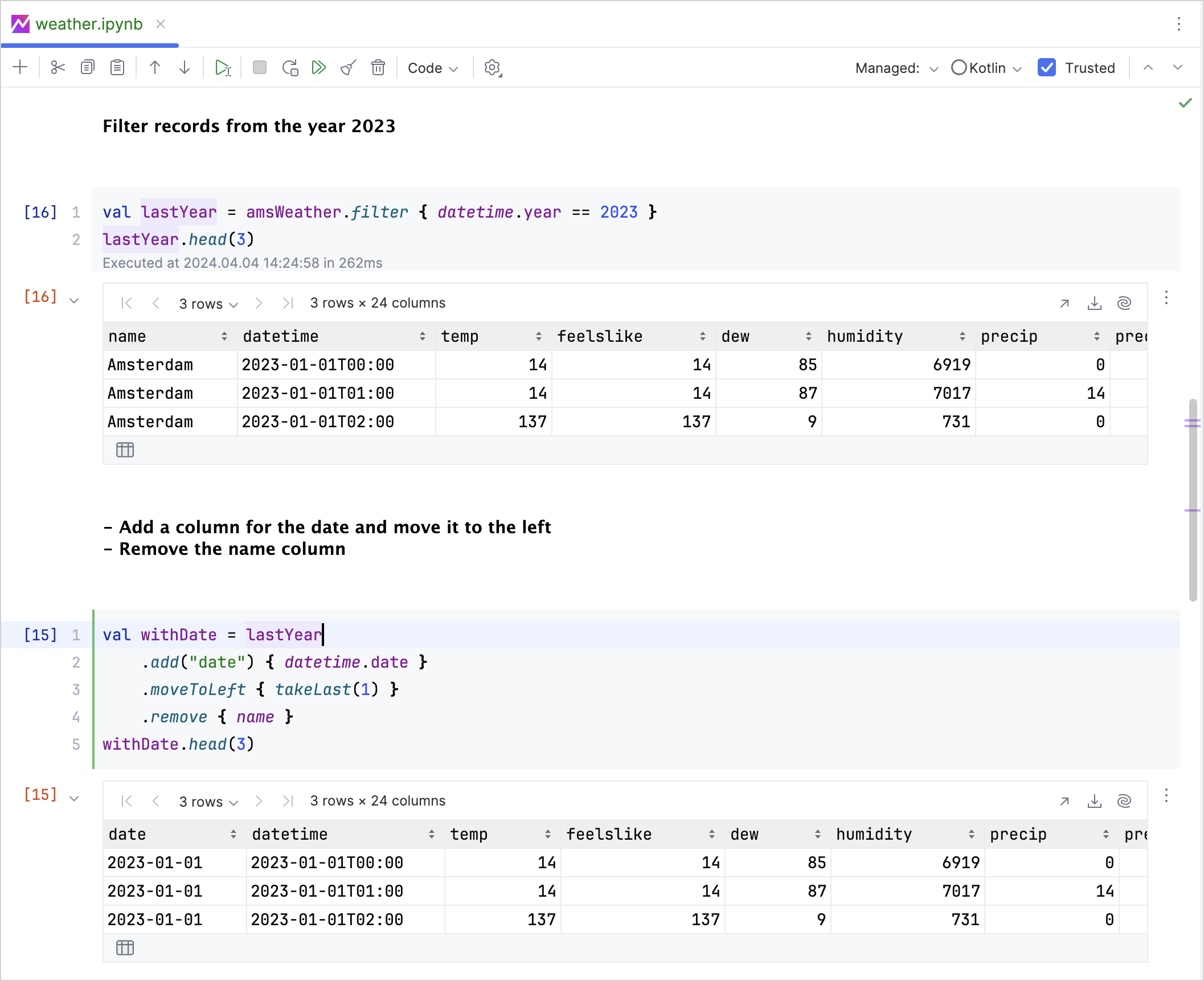
Библиотека Kotlin DataFrame позволяет работать со структурированными данными в Kotlin-проектах. Она подходит для разных этапов: от создания и очистки данных до глубокого анализа и подготовки признаков.
С Kotlin DataFrame можно работать с разными файловыми форматами, включая CSV, JSON, XLS и XLSX. Библиотека также упрощает получение данных благодаря возможности подключаться к SQL-базам данных и API. Все поддерживаемые форматы перечислены в документации DataFrame.
 {width=700}
{width=700}
Kandy
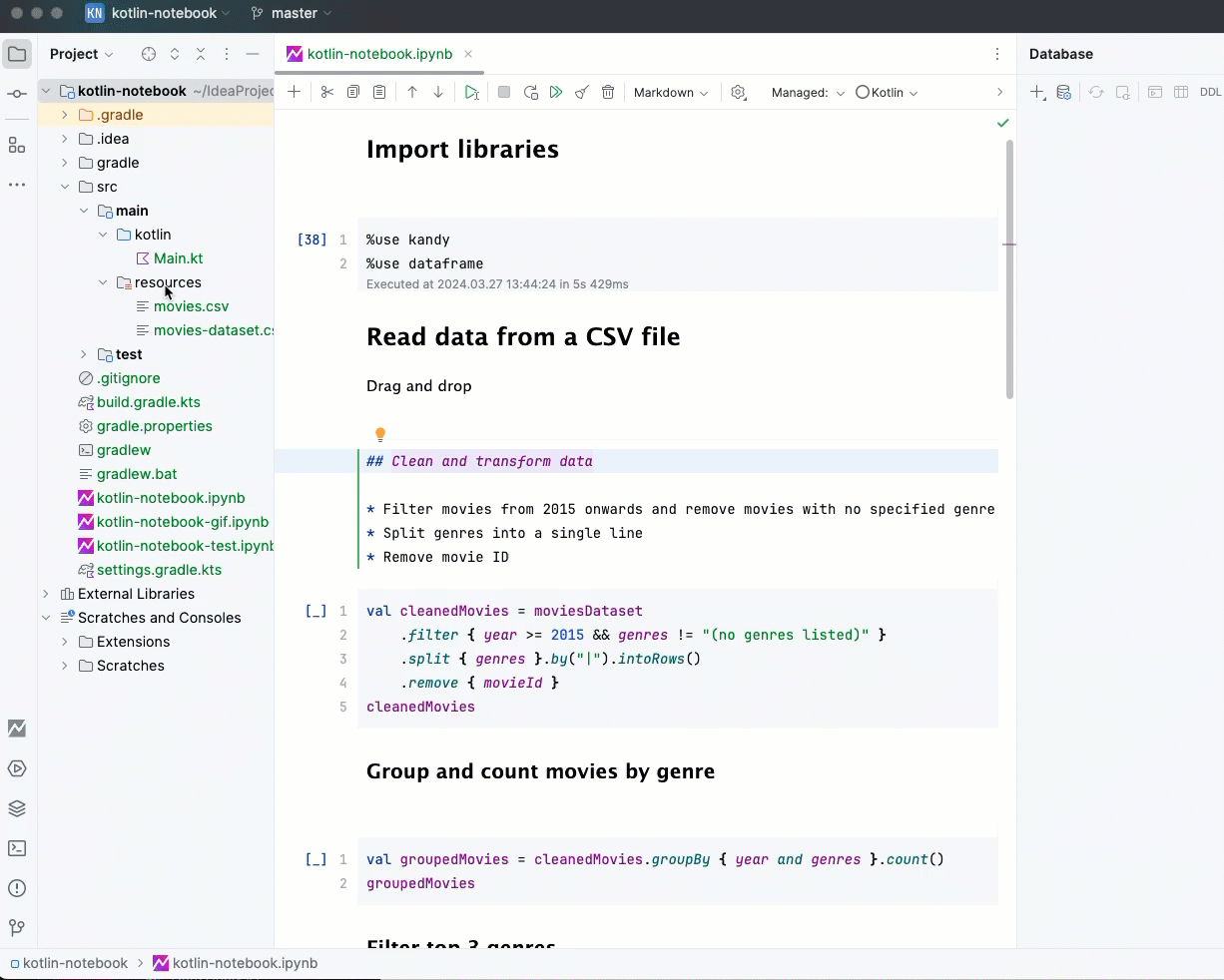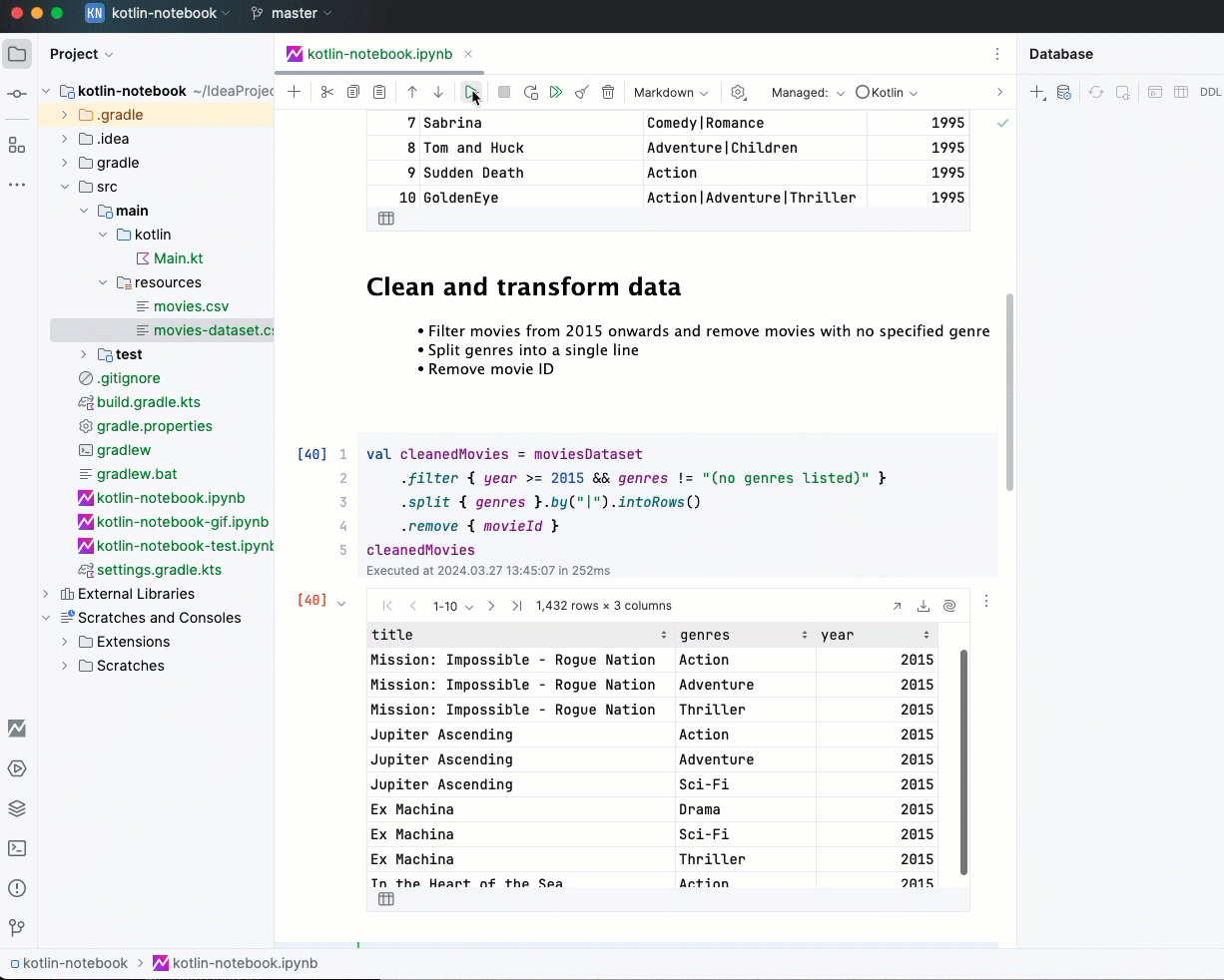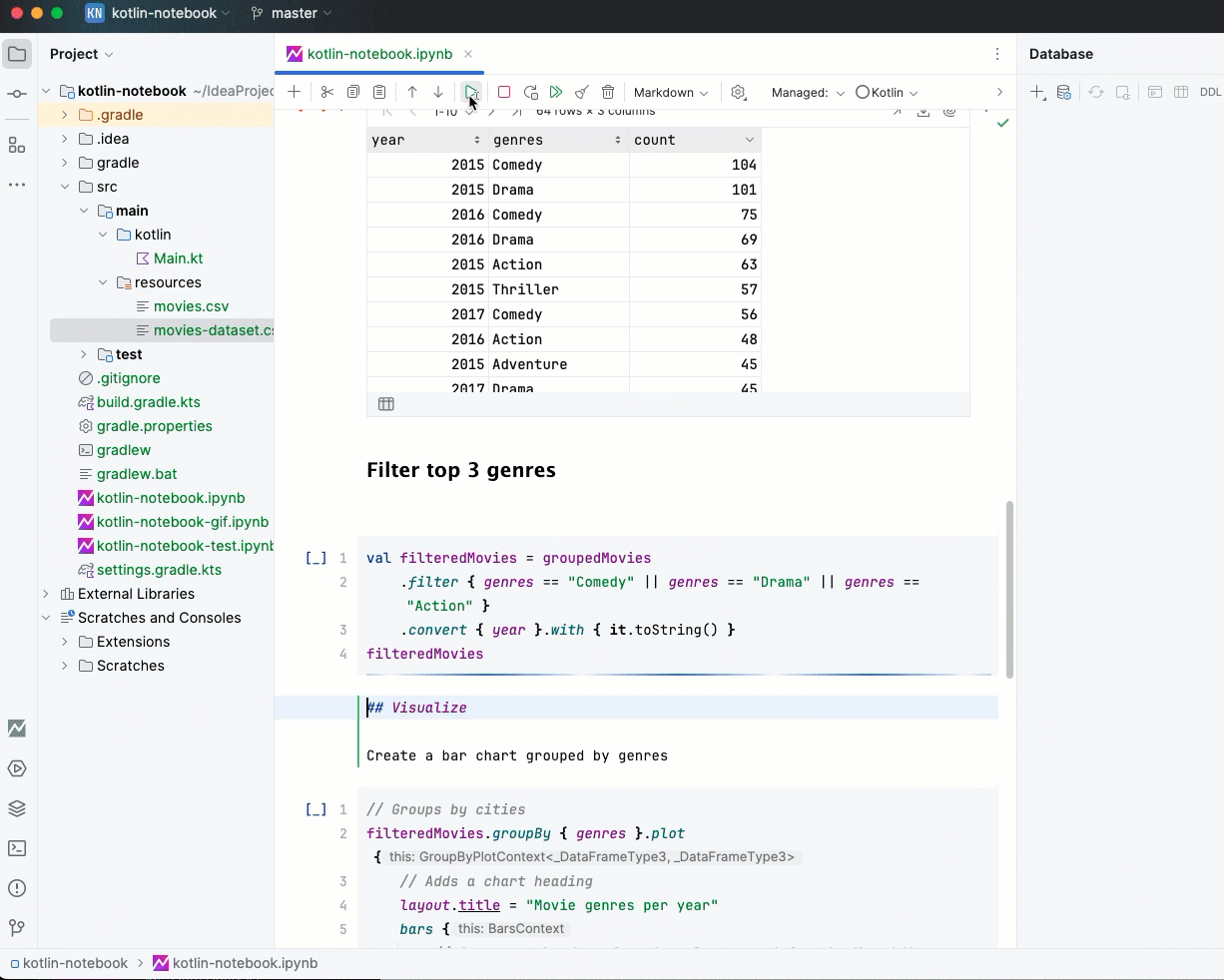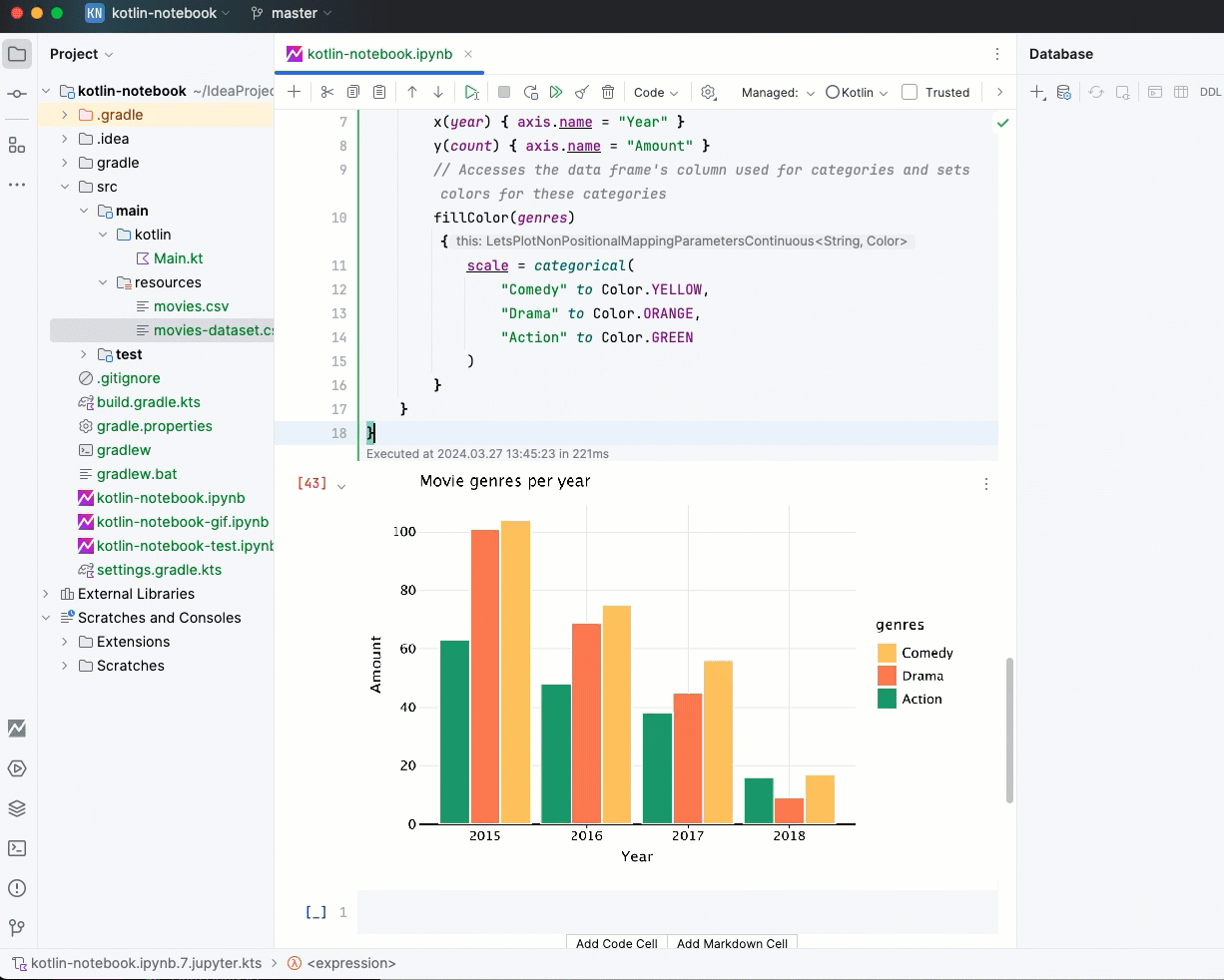
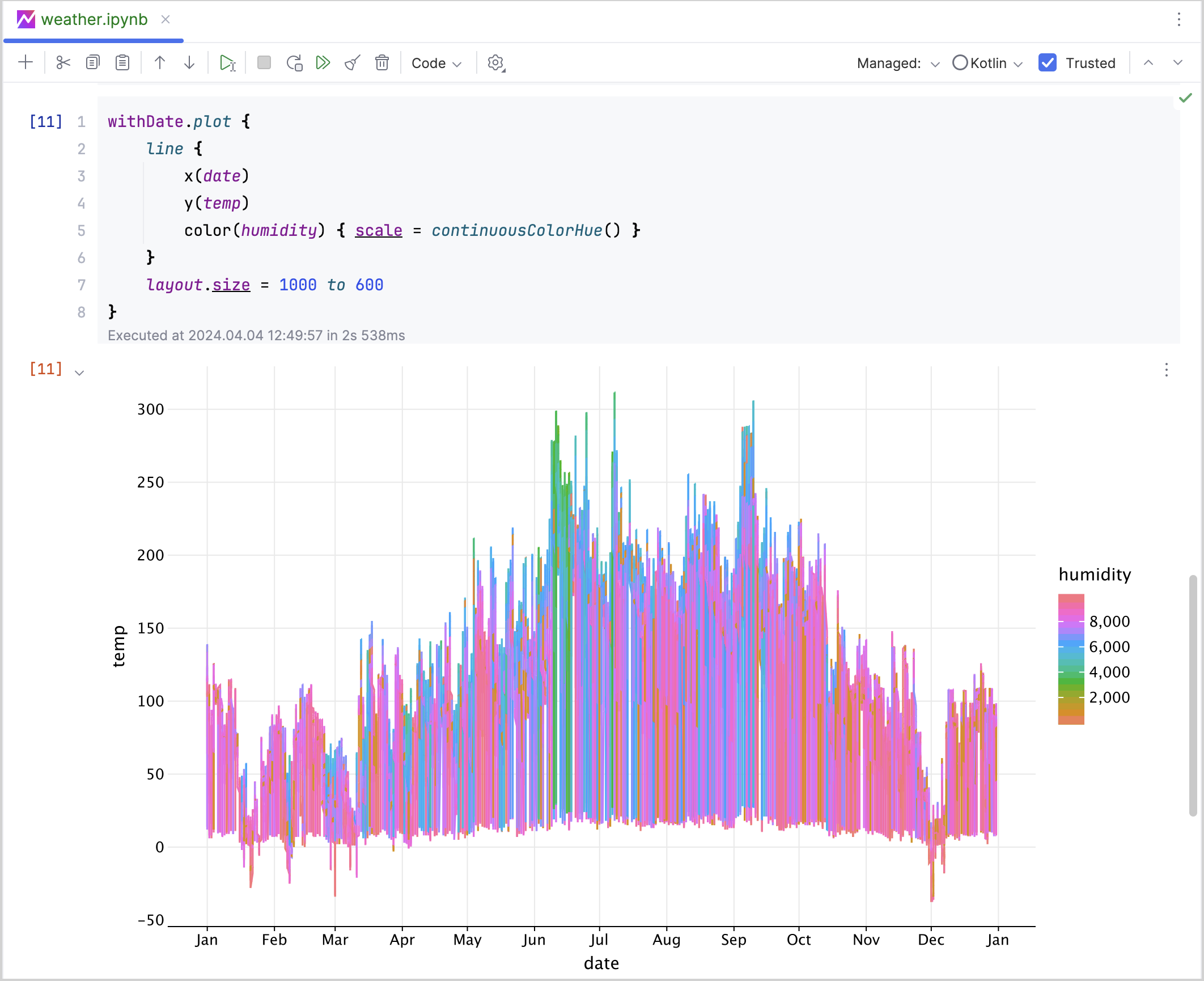
Kandy - это Kotlin-библиотека с открытым исходным кодом, которая предоставляет мощный и гибкий DSL для построения диаграмм разных типов. Это простой, идиоматичный, читаемый и типобезопасный инструмент для визуализации данных.
Kandy легко интегрируется с Kotlin Notebook, Datalore и Kotlin-Jupyter Notebook. Кроме того, Kandy удобно сочетать с Kotlin DataFrame для решения разных задач, связанных с данными.
 {width=700}
{width=700}